How to Apply Machine Learning
"We will solve it with Machine Learning!" You may have heard this phrase recently, maybe at a team meeting or in a chat on Slack. But what does that actually mean and how feasible is it to "solve" anything with Machine Learning?
In this blog post, I'll go through the common things Machine Learning is good at solving, what you need to actually solve those things, and what Machine Learning is not good at solving.For a quick refresher on the basics of Machine Learning, check out Introduction to Machine Learning.
Machine Learning Success
Machine Learning is not only very effective at many tasks, it now stands head and shoulders above everything else as a solution for many issues. A few examples:
- Image recognition - it's a bird, it's a plane, it's your face!
- Voice to text transcription
- Recommender systems - Any site that recommends a feed for you ("people who bought this also viewed this") is using Machine Learning
Large companies, such as Facebook, Apple, Amazon, Netflix, and Google (aka the FAANG) have invested tremendous resources into collecting enormous swaths of data to feed their Machine Learning algorithms, in order to create better products. The combination of faster hardware, newer algorithms, and large scale data has led to the recent boom in Machine Learning (see my previous post).
What makes it possible for Machine Learning to be really good at solving problems and what kind of problems does it struggle with? The answers lie in the data.
Machine Learning Needs Data
First, and most importantly, Machine Learning needs data. Without data you simply cannot operate Machine Learning. Let's build up our understanding with a simple example.
Imagine a program whose job it is to tell you if a shape is or isn't a dog. Let's assume that we're going to use a Machine Learning model to create the program. We want to teach a machine to tell us if a certain shape is a dog. Let's start with a flow-chart for how we want our program to work. It could look like this:
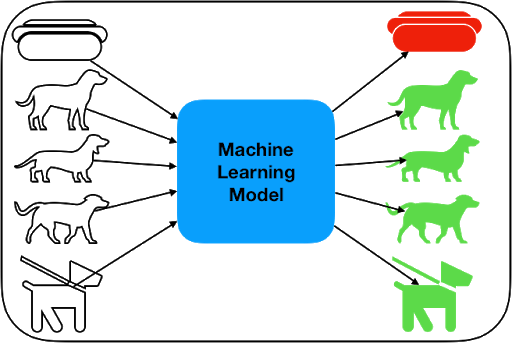
On the left side we have our input, a bunch of shapes. They are fed into the Machine Learning model which outputs the answers on the right side. As you can see, it's a fantastic model with 100% accuracy. It has successfully identified four of the shapes as dogs, by highlighting them in green. It's also very smart because it correctly identifies the hot dog as a shape that is not a dog. This simple picture depicts what a working model looks like. We put information into it and we get classifications out of it.
How do we build such a model? How does one teach a machine to correctly identify objects? As you can see, we collect data and feed it into a Machine Learning algorithm, which builds a model based on the data. More accurately, we apply algorithms to the data and hope the algorithms figure out the rules. The algorithms learn something we call a "model" and that model is able to classify new, never before seen samples. Sounds like magic, right? Let's break it down and take a look at what the data is.

Here we have a picture of labeled data. In this dataset, we have five samples, all of which are labeled as "dog" or "not dog". The idea is that, given a labeled dataset like this, a computer could look over the pictures and understand what dogs look like in comparison to what hot dogs look like.
Wait, what? How does a computer look at pictures?
I sort of tricked you there.
When a computer looks at pictures, it's actually looking at the numbers behind the pictures, which are matrices of pixel values. Given a bunch of pixel values, we can run an algorithm capable of finding a set of rules that tells us which pixels are dogs and which pixels are not.
The abstract hasn't changed, though. We give a computer a bunch of data, examples of correct and incorrect data points, and allow the computer to figure out the rules. This process is called inductive learning.
Note that for inductive learning to occur, we need labeled pictures. Pictures alone won't help us out. We need to know if the images are dogs or not. In order to teach a model how to tell is a shape is a dog, we would probably need thousands of pictures. The state-of-the-art dataset for image recognition is Imagenet, which is a collection of 14 million images with over 20,000 categories

Of course, that is an extreme case (but it is state-of-the-art). You can successfully teach a computer to recognize handwritten digits with around 60,000 samples.

My point here is that in order to teach a computer to classify an image, you need to give it many labeled samples in order for it to learn the rules.

The input to the machine learning algorithm is Labeled Data. What does the algorithm do? It attempts to learn the rules that govern the data. Given any input, it will correctly tell you what the label for that data point is.
This is typically done through an organization algorithm, but let's leave aside those details for now. What's important is that in order for it to work, we need two things:
- Data
- Labels on the data
Before I go further, I should clarify that this type of Machine Learning is actually a sub-type called Supervised Machine Learning. You can think of the labels as the "supervisors" making sure the algorithm is doing the right thing. Supervised Machine Learning is the most common because it's able to both classify and predict indicators that we're interested in. Here are a few common applications:
- Voice recognition (text to speech and speech to text)
- Image recognition
- Ad recommendations
- Language translation
All these applications are possible because of the large amounts of data available to train the models.
Machine Learning Disadvantages
Anytime data is small and the variables are large, Machine Learning will struggle. In the early days of voice assistant technology, if you said "Hey, Google, I'm feeling like killing myself", Google would simply perform a Google search and provide you with the top results. After public outcry, all large companies had to manually program their voice assistants to provide numbers for hotlines related to depression and suicide.
Machine Learning won't ever be good at answering ethical questions or solving dilemmas. There are not "right" or "wrong" answers to ethical debates, so we cannot have a labeled dataset. Similarly, anytime a question is in a "grey" area, Machine Learning will struggle. What is the best food to feed your baby? How should you figure out seat planning for your wedding reception? Better leave these questions for the socially adept. There are too many confounding factors to plug into a simple equations. Just ask the non-socially adept who don't understand why Uncle Mark can't sit next to cousin Jackie.
Andrew Ng famously said, "If a typical person can do a mental task with less than one second of though, we can probably automate it using AI either now or in the future." The caveat to this statement is "with a large and well labeled dataset that described the task".
What Does This Mean for You?
When someone tells you, "Hey! I'd like to develop a program that can automatically classify different kinds of cucumbers", you need to ask "What kind of data do you have?" and "Are you prepared to manually label thousands of cucumbers?"
In other words, when someone says, "Let's make an AI program that can tell us if someone is attacking our network", you now know to ask the following:
- What kind of data do we have? (for pictures, it's pixels and for network traffic, it may be pcap files)
- Is it labeled?
- Is the amount of data sufficient?
I have personally discovered many people have good ideas, but don't realize the amount of data required, or even that data is required to make Machine Learning work.
Now you understand the flow of a Machine Learning model and how to train a model with data, allowing the algorithms to learn the rules. In my next post, I'd like to discuss the importance of metrics on your models. How do you know if you have a good model? How do we define success in Machine Learning?
Be sure to discover a variety of technologies and their capabilities in INE's expert courses, taught by industry professionals.
Until next time!
Learn more about building deep learning models in Gilad's course, now available:
{{cta('b45204e1-6662-4cc5-8c14-4ac60f14c6fc')}}
Share this post with your network